
devtools::source_gist("21c6a40c78fd66d708bec45d5c0b52e2")
Update
Substantial changes to these functions are explained here: jmclawson.net/posts/updates-to-word-vector-utilities/
This July, I was very fortunate to be a participant at the Word Vectors for the Thoughtful Humanist workshop, organized by the Women Writers Project at Northeastern University and funded by the NEH. Sarah Connell and Julia Flanders, along with Laura Johnson, Ashley Clark, Laura Nelson, Syd Bauman, and others, guided us through introduction, discussion, and practical application of word vector embeddings. I left Boston with a new understanding of some tricky concepts, a new sense of how I might use these techniques in my work, and a new network of workshop participants and leaders to continue learning from and with. The whole experience far exceeded my expectations, and the travel funding they offered made my participation possible.1
While we began by using models that the workshop leaders built for us in the months leading up to the workshop, we also created our own models using Ben Schmidt’s wordVectors package and the RMarkdown files provided by the Women Writers Project, “Word Vectors Intro” and “Word Vectors Template”. Expanding on what I learned from the workshop, I’ve since standardized some of my workflow in the form of utility functions, which I’m oversharing in this post. These functions can be loaded with the following line in RStudio:2
1 Preparing and Modeling a Corpus
The Women Writers Project’s template files walk through the process for preparing and processing a corpus to train a model, explaining some best practices along the way. While training multiple models for different subsections of my corpus, I kept losing track of where I was in the process, so I boiled these things down from about sixteen lines in the template to two functions.
Before doing anything in R,3 it’s necessary to have the corpus materials organized in a way that the scripts know how to understand. Outside of R, organize files the following way:
- Within the working directory, create a subdirectory called
data. - Within that
datadirectory, create a subdirectory namedYourModelName, giving it whatever name will be used for the model. Keep in mind, this name will persist into future steps, so name it something short, meaningful, and useful. - Save the corpus files as plain text files within this
YourModelNamedirectory.
1.1 prep_model()
Once text files are organized accordingly, go back into RStudio, load the gist using the above source_gist() command, and then prepare each corpus using the command prep_model(model="YourModelName"), using whatever model name chosen for the directory, above.4
prep_model("WomensNovels")This first command is nothing more than a wrapper simplifying six lines from the WWP template. In the data subdirectory, it will save two text files whose filenames begin with the name of the model: in my case, “WomensNovels.txt” contains all corpus texts within a single file, and “WomensNovels_cleaned.txt” replaces all uppercase letters with lowercase; if the optional bundle_ngrams parameter had been set to anything but the default, this second text file would also include ngram bundling.
1.2 train_model()
After running that first command, this second command will carry things through the rest of the way:
train_model("WomensNovels")The second command does a bit more than the first. In addition to simplifying about ten lines from the Women Writers Project’s template using reasonable default settings, this second command will create a new object named WomensNovels in the global environment and store these parameter settings for later recall.5 Setting defaults are vectors=100, window=6, iter=10, negative_samples=15, threads=3; these can each be changed within the train_model() call, and they can later be recalled with the attributes() function:
attributes(WomensNovels)$windowwindow
6 attributes(WomensNovels)$negative_samplesnegative_samples
15 As part of the wordVectors package, a trained model will be saved in the data directory, for instance as “WomensNovels.bin”. And as part of these utility functions, the parameter settings will be saved alongside these “.bin” files as metadata_YourModelName.Rdata—in my case as “metadata_WomensNovels.Rdata”. After a model has been trained and saved to disk, it can be recalled into memory in a later R session using the train_model() function, which will also load any existing metadata:
train_model("WomensNovels")2 Working Directly with Data
2.1 make_siml_matrix()
Once the models are trained, additional utility functions provide some ways to explore the results. Most useful among these is the make_siml_matrix(wem, x, y) function, which makes it easy to see how one group of words x relates to another group of words y within a single model wem.
make_siml_matrix(WomensNovels,
x=c("sweet", "bitter", "fresh", "hot"),
y=c("bread", "sea", "attitude", "air")) sweet bitter fresh hot
bread 0.3408684 0.2231573 0.4800544 0.4845648
sea 0.3286719 0.1064460 0.2720364 0.4040408
attitude 0.2924267 0.4117849 0.2358243 0.1779941
air 0.2132098 0.1775206 0.2999856 0.1284261The make_siml_matrix() function returns a matrix of cosine similarity values for each comparison among the two groups of words. Here, it shows that hot and bread are the nearest words among these two groups in the WomensNovels corpus, since the highest value is in the bread row and the hot column. It’s still necessary to interpret these results, probably even making the judgment call that a similarity of 0.485 isn’t very high even if it is the highest in this set, but the function makes some of this process simpler.
These cosine similarity values measure how likely any two words are to be used in the same context—either near each other or near the same words. Any two words with strongly dissimilar meanings may appear in similar scenarios, so it’s unsurprising if antonyms show high cosine similarity:
make_siml_matrix(WomensNovels,
x=c("good", "healthy", "high", "bright"),
y=c("bad", "ill", "low", "dark")) good healthy high bright
bad 0.4892814 0.3720099 0.2449388 0.22157602
ill 0.5740076 0.3516507 0.2686943 0.03634597
low 0.2212564 0.3649225 0.1946395 0.29597524
dark 0.1955804 0.4216446 0.3700006 0.54517738Here, the relationships of ill / good and bright / dark show the highest cosine similarities, higher even than the relationship of hot / bread. I was expecting the paired antonyms to show the highest cosine similarity values, but that doesn’t seem to be the case in this limited corpus.
Any matrix can be exported using the standard write.csv() command. This example also shows that it’s possible to use vectors with these functions.
v_man <- c("man", "husband", "father", "son")
v_woman<- c("woman", "wife", "mother", "daughter")
male_female <- make_siml_matrix(WomensNovels, x=v_man, y=v_woman)
write.csv(male_female,file="man_woman.csv")3 Visualizing Relationships
3.1 cosine_heatmap()
The utility functions also include a couple to explore the data visually. The first of these, cosine_heatmap(), makes it easy to visualize a heatmap of the above matrix:
cosine_heatmap(WomensNovels,
x=c("sweet", "bitter", "fresh", "hot"),
y=c("bread", "sea", "attitude", "air"))Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.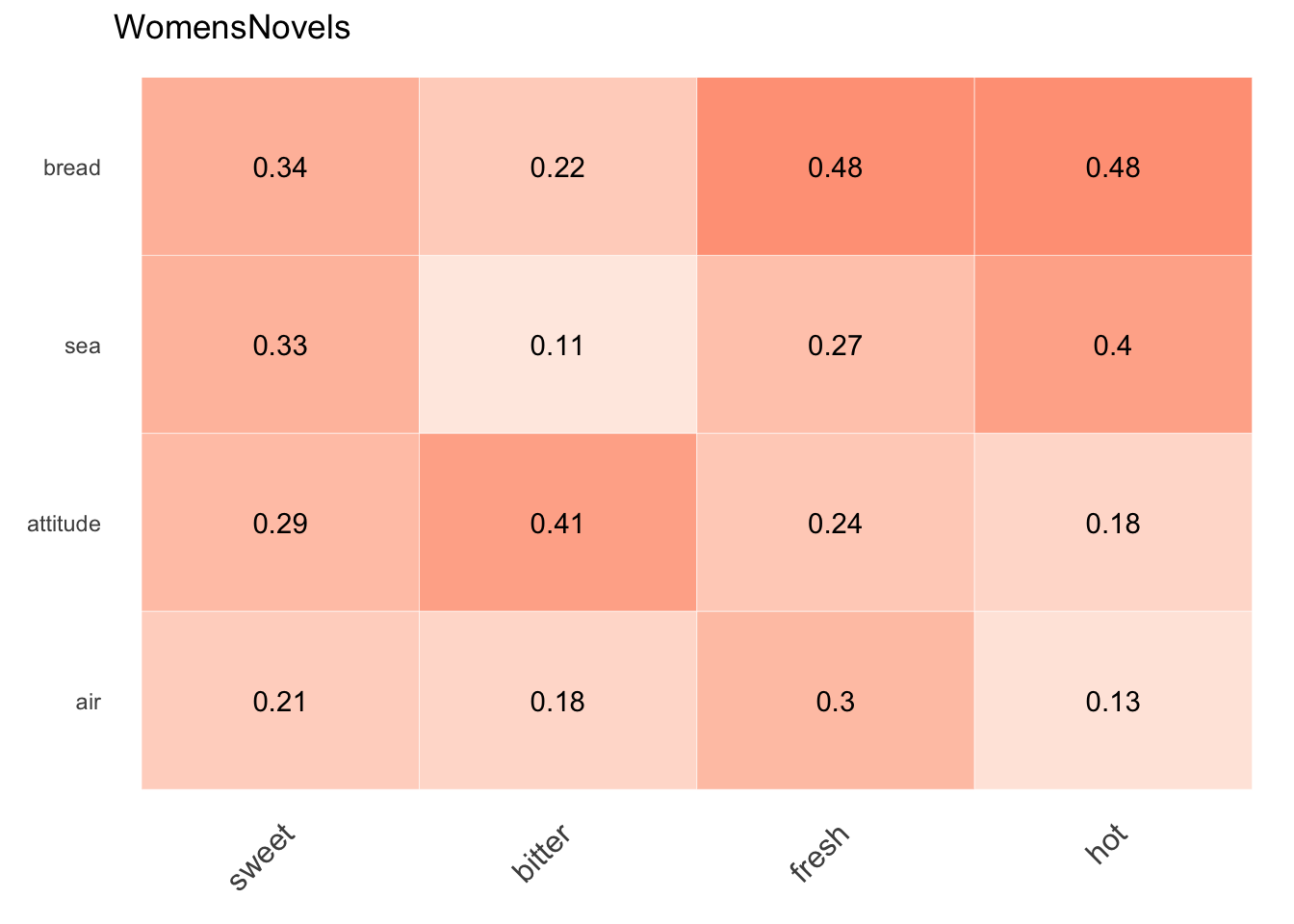
Adding color to the similarity matrix makes the data easier to read quickly. And by default, the name of the model (here, WomensNovels) is printed at the top, aiding comparisons of heatmaps from multiple models.
Matching x and y values can be a good way to provide context in a comparison. Since a strong relationship shows up as a bold red, this redundant comparison results in a clear diagonal:
v_doubt <- WomensNovels %>%
closest_to(~"doubt" + "truth") %>%
.$word
cosine_heatmap(WomensNovels, v_doubt, v_doubt)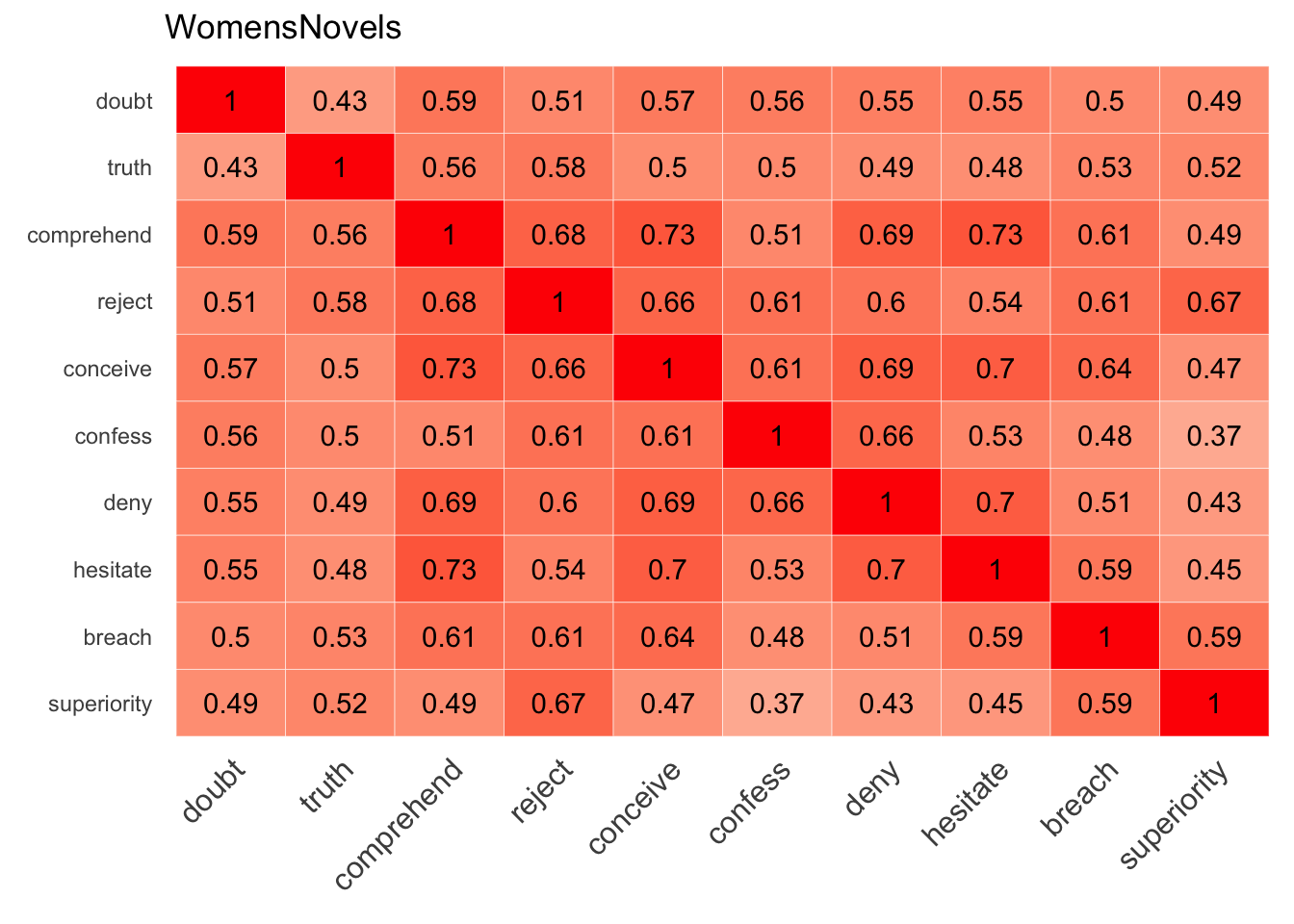
wem, x, y, it’s ok to skip naming the parameters to save space. In other words, cosine_heatmap(wem=A,x=B,y=C) is the same as cosine_heatmap(A,B,C).When using x and y values that equal each other like this, it may be nice to simplify things, showing only half of the heatmap by turning off the redundant toggle:
cosine_heatmap(WomensNovels,
x=v_doubt,
y=v_doubt,
redundant = FALSE)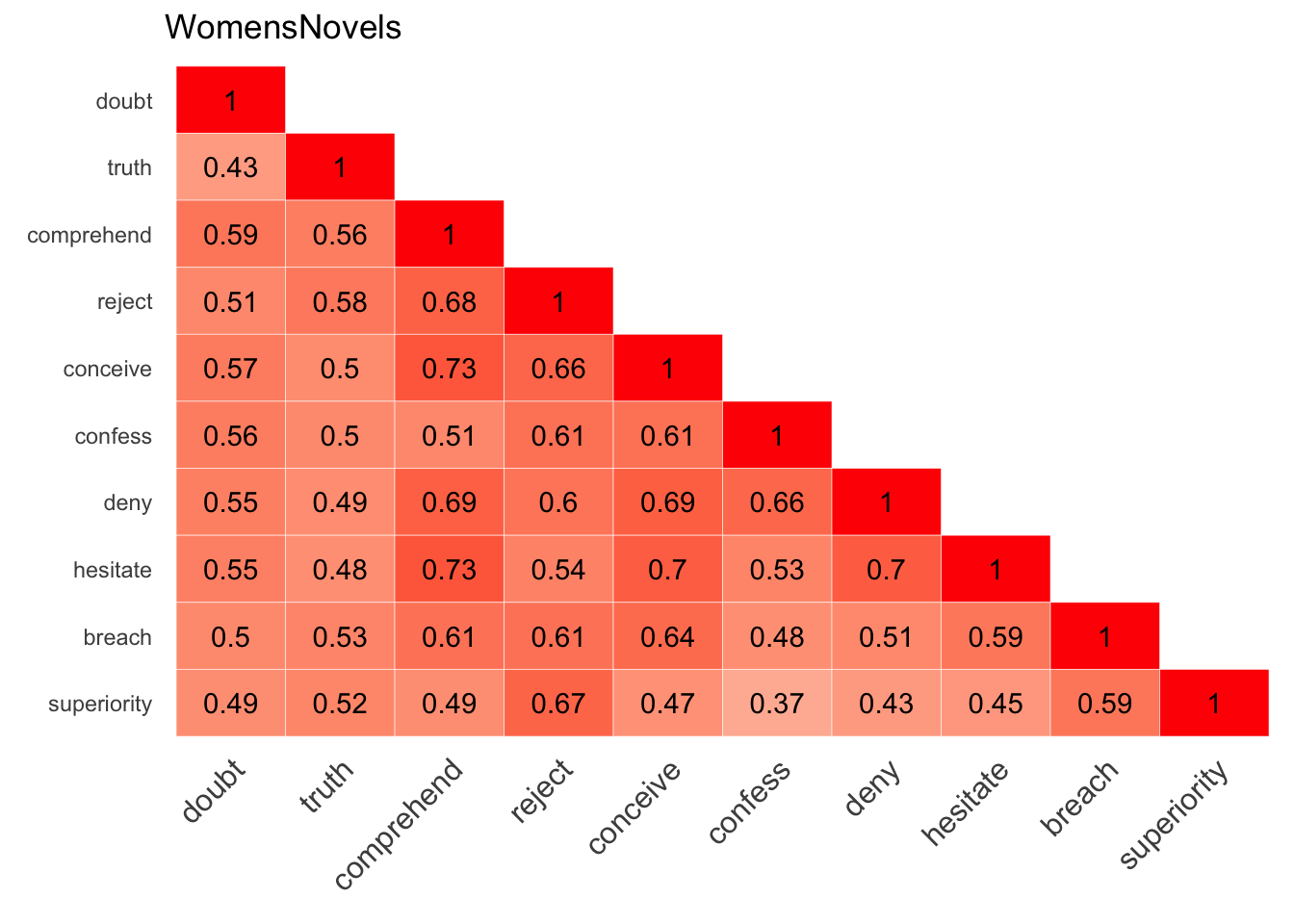
As noted above, the command works with a vector of values, but it’s also possible to be trickier, combining the function with the closest_to() command from the wordVectors package:
cosine_heatmap(WomensNovels,
x=closest_to(WomensNovels, "man", 15)$word,
y=closest_to(WomensNovels, "woman", 15)$word)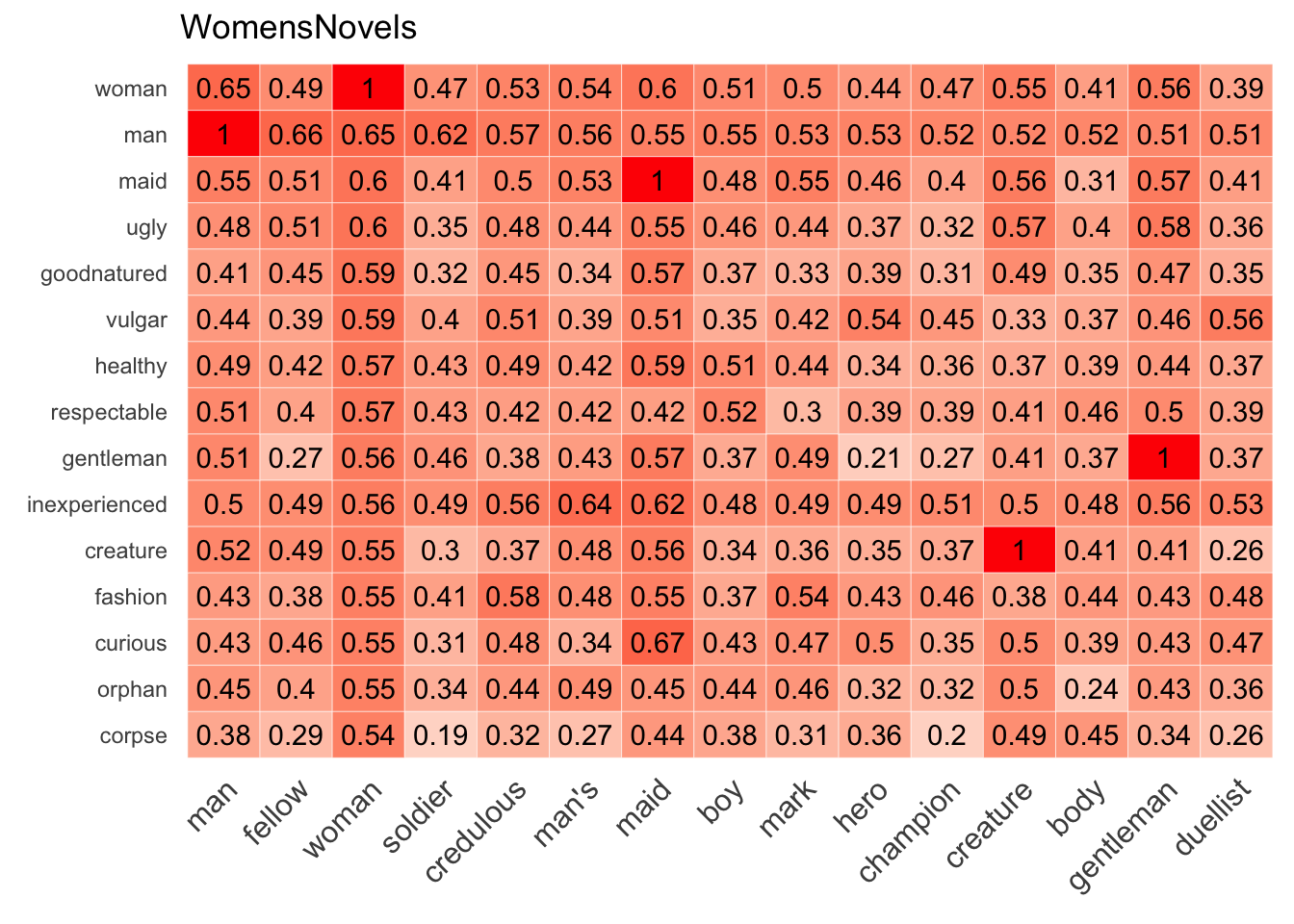
closest_to() command here, don’t forget to add $word at the end, dropping the numeric values and returning only the words themselves.By default, these heatmaps round values to two digits right of the decimal point, but it’s possible to change this setting by setting the round parameter to another number like round=3. It’s also possible to hide values altogether when they’re not necessary for exploring a model or if a heatmap gets too tight:
cosine_heatmap(WomensNovels,
x=closest_to(WomensNovels, "man", 25)$word,
y=closest_to(WomensNovels, "woman", 25)$word,
values=FALSE)
values parameter is set to FALSE, the function displays a legend by default. In practice, a cosine similarity of -1 is probably unlikely, as (I think) the model relies heavily on negative sampling to get anything less than 0.3.2 amplified_heatmap()
The second function for visualizing results helps to amplify comparisons within each row and column. This function merely strengthens signals it finds within a subset of words; it doesn’t validate these signals, so it’s necessary to be careful about attributing too much importance to cosine similarity values that may actually be meager.
amplified_heatmap(WomensNovels,
x=closest_to(WomensNovels, "man", 25)$word,
y=closest_to(WomensNovels, "woman", 25)$word)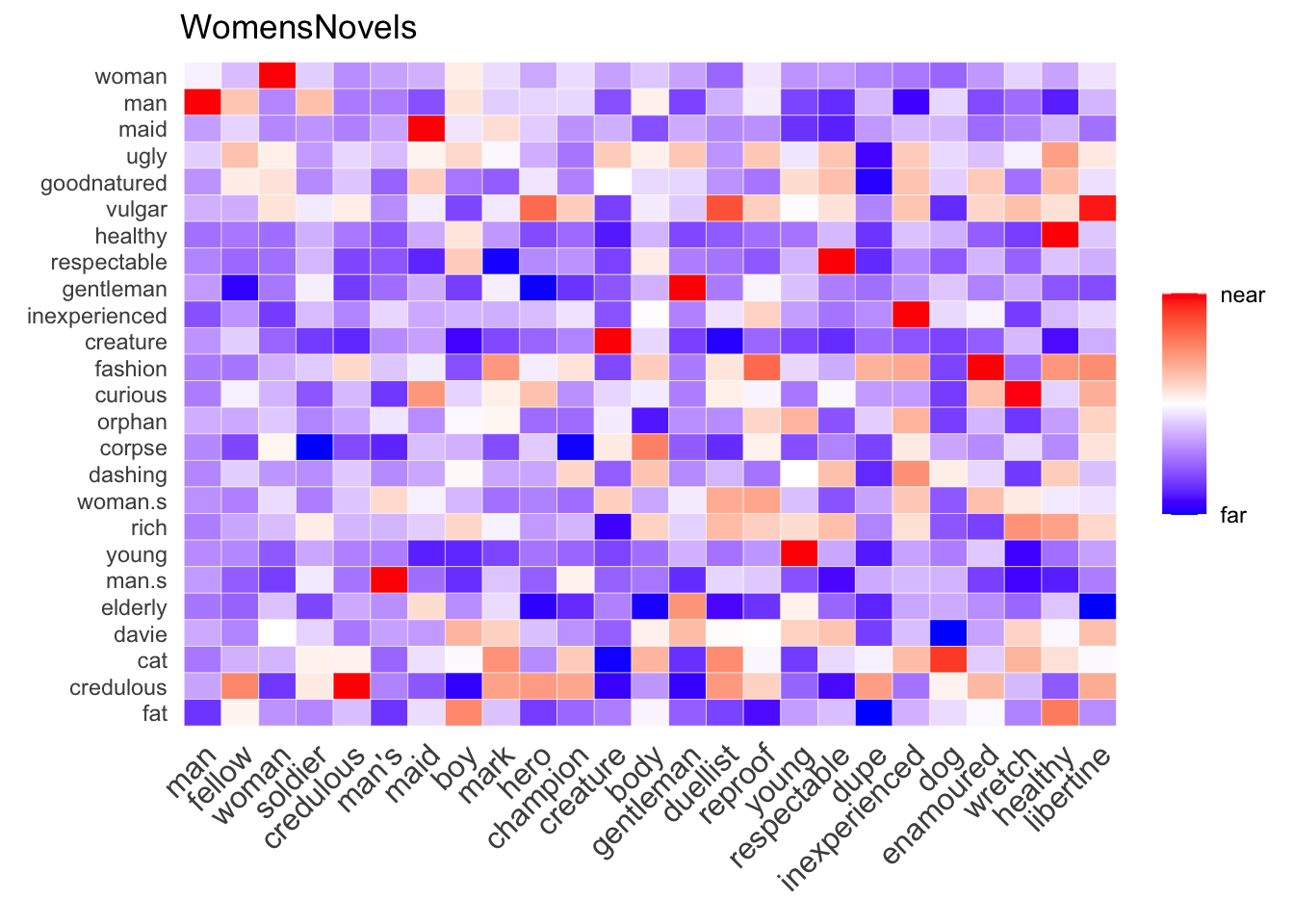
Many of the same parameters used with cosine_heatmap() work for amplified_heatmap(), too. But as this second function amplifies the highest and lowest values for each row and column, results become less useful for sets with any words appearing on both the x and y axes; for these, it’s probably a good idea to toggle the diagonal parameter to FALSE:
amplified_heatmap(WomensNovels,
x=c(v_man, v_woman),
y=c(v_man, v_woman),
diagonal = FALSE)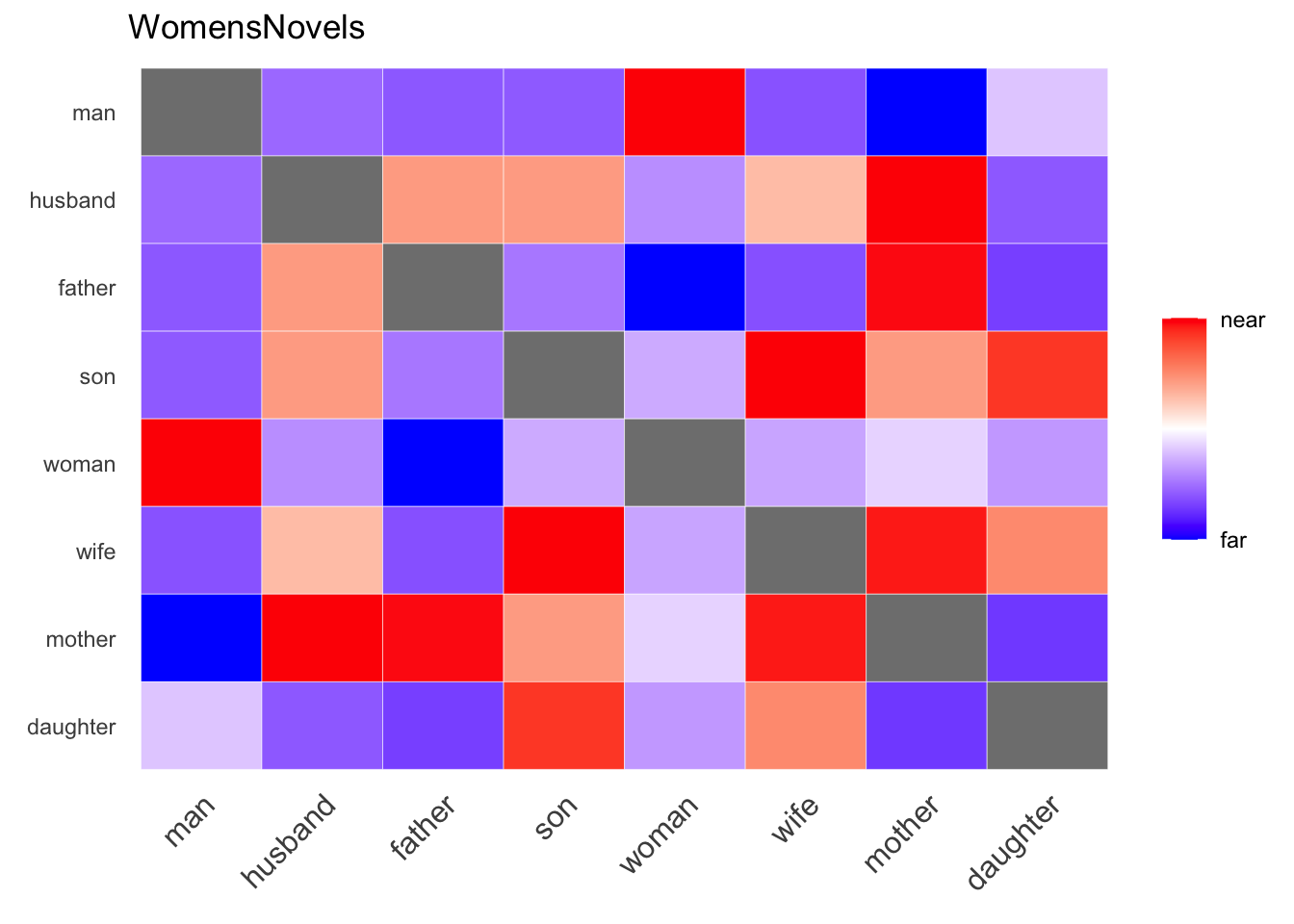
diagonal=FALSE hides the obviously strong connections between a word and itself by making these cells gray and leaving space on the spectrum to amplify lower-ranked values. As always, a strong red signifies that two words are more similar to each other, while a strong blue indicates they’re much more dissimilar, relative to other words in each row and column.4 Iterative Exploration
Ideally, the process of visualizing sets of words will lead to iterative development of a research question, as new relationships are suggested in unexpected heat patterns. What, for instance, can be made of the unusually hot cell at the bottom of the the first amplified heatmap above, where the fat row meets the healthy column? First checking it out with cosine_heatmap() is a good idea to verify that the numbers justify going further:
cosine_heatmap(WomensNovels,
x=closest_to(WomensNovels, "healthy", 10)$word,
y=closest_to(WomensNovels, "fat", 10)$word,
round=3)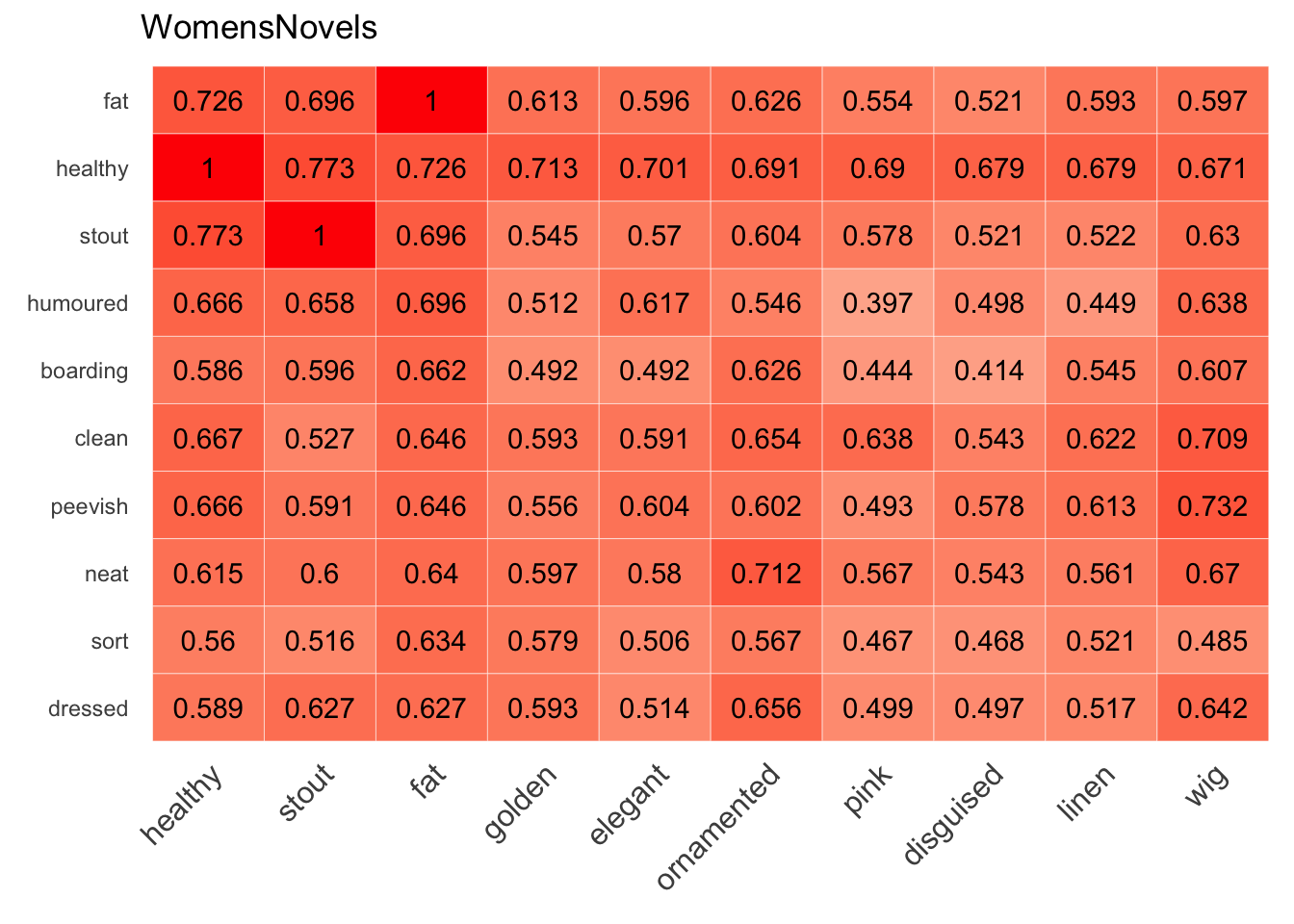
These values look high enough to warrant exploration, so a second step might be to widen the scope and discover any other relationships revealed by an amplified heatmap:
amplified_heatmap(WomensNovels,
x=closest_to(WomensNovels, "healthy", 30)$word,
y=closest_to(WomensNovels, "fat", 30)$word,
legend = FALSE,
diagonal = FALSE)
legend=FALSE parameter, making more space for more words.At this point, someone working with this corpus might continue exploring the relationship of fat to healthy, or they might be inspired by other relationships. For instance, is there something interesting in the relationships of portrait / fashion and proportioned / painted? In what ways do texts draw upon the language of art to establish expectations of beauty, and do they leave room in the conversation for health?
5 In Practice
I’ve already been using these utility functions to build word embedding models of subsets of my corpus and to begin to explore and compare relationships among the words. I’m very excited by this ongoing work, and I’m having fun doing it, discovering the kinds of connections of ideas and implications that can be found in my corpora, but I wanted to document some methods in progress and to share them. I hope they prove useful to others.
Footnotes
In case it’s not obvious from the subdued tone here, I recommend it very highly! Visit their website to see details about attending one of the remaining three workshops.↩︎
The gist is available here. In order to load it remotely, the
devtoolspackage will need to be installed if it’s not yet on the system, but it’s also possible to paste the source into a local file.↩︎Well, it’s a good idea first to double check the working directory in R using
getwd().↩︎For these examples, I’m using the sample corpus the Women Writers Project makes available here, and I’m naming my model
WomensNovels.↩︎Since training the model may take many hours, and since there’s no built-in way to go back in time to check what parameters were used, workshop leaders strongly urged us to take note of these parameters before beginning this step. Taking note of these parameters is still a good idea, but this wrapper function adds some backup.↩︎
Citation
BibTeX citation:
@misc{clawson2019,
author = {Clawson, James},
title = {Word {Vector} {Utilities}},
date = {2019-08-12},
url = {https://jmclawson.net/posts/word-vector-utilities/},
langid = {en}
}
For attribution, please cite this work as:
Clawson, James. “Word Vector Utilities.” jmclawson.net, 12 Aug. 2019, https://jmclawson.net/posts/word-vector-utilities/.