library(rvest)
library(dplyr)
library(ggplot2)Selecting a sufficiently sized collection of texts for historical analysis is tough. When I try to list all the novels I can think of to provide context for a project, I’m bound to get it wrong some way: I fail by forgetting something important, or I succeed only in reproducing my own limitations.
In this post, I explain my rationale and process for using R to select a reasonable, medium-sized sample of titles from Wikipedia for historical comparison; a later post will go farther, showing how to use this selection to get the texts themselves from Project Gutenberg. Even though the process might seem obvious, I’m sharing in part to remind myself of the decisions I took. And with luck, my workflow might prove useful to someone else, too.1
1 Why Wikipedia?
If nothing else, Wikipedia is a powerhouse. Rough Googling tells me that the online encyclopedia has 29 million entries in English, and the number of contributors is certainly large enough that I don’t even want to devote the time to estimate it.2 And since it was founded in 2001, it has seldom suffered a reputation for being completely untrustworthy: even though it’s the final say in almost nothing, it’s a perfectly acceptable first source in many topics.
But when it comes to certain questions, Wikipedia’s authority shines stronger. When selecting things for being well known—say, for identifying a canon of literature—a crowd-sourced resource like Wikipedia is especially convenient. As it is (and with many caveats), canon is shaped when the chaff of obscure works float away in the winds of time and collective ignoring, leaving behind the only works that will have a chance to matter. Because of its size, Wikipedia is big enough that its gusts of collective ignoring blow twice as hard, and we can get a sense of what may become canon before time has a chance to pass.
Even as Wikipedia is limited as a compendium of objectivity, it is laudable for what it offers as a snapshot of subjectivity. A cultural artifact in its own right, it provides a sampling of the kinds of things that will have mattered. For studying literature younger than a few hundred years, it can be invaluable.
2 Defining the Scope
To get started in using Wikipedia to select a corpus, first load the necessary packages in R. For this project, I use rvest to scrape information from web pages, dplyr to reshuffle information, and ggplot2 to make sense of the selection visually. If any of these packages isn’t already installed, be sure to install it using the install.packages command in the console.
Next, define where the corpus is coming from. The crowd-sourced nature of Wikipedia’s category pages is incredibly useful, as they supply lists of novels considered by others to be important, including some useful metadata. The URLs to any similarly structured Wikipedia pages might be used here.3 It’s a good idea to download the files locally to reference them without being a nusiance to Wikipedia. Then, once these webpages are local, the computer can read the HTML and interpret it to find the lists of links to the pages for individual years.
For my interests in this project, I’m curious about selecting out-of-copyright works in English, so I’m looking first at the Wikipedia categories for 19th-century American novels.
wp_categories_american <- "https://en.wikipedia.org/wiki/Category:19th-century_American_novels"
# Avoid hitting Wikipedia's servers too much.
# Download pages only if they haven't been downloaded
if(!file.exists("American-years.html")){
download.file(wp_categories_american,
destfile = "American-years.html")}
# Parse for individual years
wp_years_links_amer <- read_html("American-years.html") %>%
html_nodes("a.CategoryTreeLabelCategory") %>%
html_attr("href")It turns out that the Wikipedia pages are not as tidy as they could be, so it’s probably necessary to select a subset of the list, limiting results only to those items that are actually links to years. In my case, I just drop off the last few items of the list by defining the final item as number 81.
wp_years_links_amer <- wp_years_links_amer[1:81]2.1 The data so far…
At this point, the data in R for my project includes a list of 81 URLs for pages listing every available novel categorized as American and from a particular year between 1801 and 1900. To grab one at random, the sixtieth item in the list is the URL for the Wikipedia page listing all those novels categorized as 1880 American novels. Following that link will show that this webpage is another list, containing a list of seven novels.
Seven novels may seem reasonable to keep track of, but those are just the American novels for one year. With 81 years to choose from and potentially more years for other categories, it’s easy to see why scripting this process is the best way to keep everything organized.
3 Getting Titles
After downloading and analyzing the category page for the scope of the corpus, the next step is just a variation of the same step. But instead of downloading the overall national category page to scrape links to the year subcategories, we’re downloading the year subcategory pages to scrape links to novel pages.
Because 100 years per century is a lot of quick hits to a web server, I added a randomized wait time after downloading each page. Otherwise, I worried Wikipedia might discover that I was just a bot.4 The “number” in the definition of my function is to allow for downloading small batches, but it probably is overkill to pair it with the wait time.
After defining this function, I ran it for the group of American novels and watched the files collect in the folder of my operating system:
download_wikipedia_pages <- function(pagelist=wp_years_links_amer, number=5, group="American"){
# define a directory
thedir <- paste(group,"years/",sep="-")
# use the list of links to define years
theseyears <- as.numeric(gsub("[^0-9]","",pagelist))
# list the available years that have not been downloaded
already.downloaded <- list.files(thedir)
already.downloaded <- gsub(".html","",already.downloaded)
# exclude any years already downloaded
if(length(already.downloaded)==0){
pagelist2 <- pagelist
} else {
pagelist2 <<- pagelist[-grep(paste(already.downloaded,collapse="|"),pagelist)]
}
theseyears <<- as.numeric(gsub("[^0-9]","",pagelist2))
if(length(pagelist2)==0){
message("Everything is already downloaded.")
} else {
if(number>length(pagelist2)){number=length(pagelist2)
}
# for each year, for as many as "number" years, download the page,
# save it, and then wait a random number of seconds before
# downloading the next year in the list.
for (page in pagelist2[1:number]) {
thisyear <- as.numeric(gsub("[^0-9]","",page))
thisurl <- paste("https://en.wikipedia.org",page,sep="")
if(!dir.exists(thedir)){
dir.create(thedir)
}
download.file(thisurl,
destfile = paste0(thedir,"/",thisyear,".html"))
randomtime <- sample(1:15,1)*sample(c(0.5,1,pi/2),1)
cat("Wait for",randomtime,"seconds")
Sys.sleep(randomtime)
}
}
}
# Download the year subcategory pages
download_wikipedia_pages(pagelist=wp_years_links_amer, number=100, group="American")With all these pages downloaded locally, another function gets the lists of titles from each of the downloaded pages. I ran this function on the whole American group and checked the first few results. They mostly look ok, but that fifth item may be a problem:
get_titles <- function(years=1801:1900,group="American"){
works_df <<- data.frame(titles=c(),year=c(),group=c())
available_years <- intersect(years,gsub(".html","",list.files(path=paste(group,"years",sep="-"))))
for(year in available_years){
titles <- read_html(paste(paste(group,"years/",sep="-"),year,".html",sep="")) %>%
html_nodes("div#mw-pages") %>%
html_nodes("div.mw-content-ltr") %>%
html_nodes("li") %>%
html_text()
thisyear_df <- data.frame(titles=as.character(titles),year=as.numeric(year),group=group)
works_df <<- rbind(works_df,thisyear_df)
}
}
# Parse titles
get_titles(group="American")
kable(works_df[1:5,])| titles | year | group |
|---|---|---|
| Clara Howard | 1801 | American |
| Equality; or, A History of Lithconia | 1802 | American |
| Memoirs of Carwin the Biloquist | 1803 | American |
| Kelroy | 1812 | American |
| Precaution (novel) | 1820 | American |
Titles with parenthetical notes added to them may pose difficulties if we ever want to use these titles later on to cross-reference against titles from other datasets.5 So another function tidies things up easily. Running this latest function and checking the data for cleanliness shows that things are much improved:
clean_works_df <- function(){
works_df2 <<- data.frame(works_df,possibleauthor=as.character(""), stringsAsFactors=FALSE)
works_df2$titles <<- as.character(works_df2$titles)
sub_index <<- grep(" novel)",works_df$titles)
for (index in sub_index){
title_parts <- unlist(strsplit(as.character(works_df$titles[index])," \\("))
works_df2$titles[index] <<- title_parts[1]
works_df2$possibleauthor[index] <<- as.character(gsub(" novel\\)","", title_parts[2]))
}
sub_index <<- grep("(novel)",works_df$titles)
works_df2$titles[sub_index] <<- gsub(" \\(novel\\)","",works_df2$titles[sub_index])
sub_index <<- grep("(book)",works_df$titles)
works_df2$titles[sub_index] <<- gsub(" \\(book\\)","",works_df2$titles[sub_index])
sub_index <<- grep("(novella)",works_df$titles)
works_df2$titles[sub_index] <<- gsub(" \\(novella\\)","",works_df2$titles[sub_index])
}
# Tidy the titles
clean_works_df()
kable(works_df2[1:5,])| titles | year | group | possibleauthor |
|---|---|---|---|
| Clara Howard | 1801 | American | |
| Equality; or, A History of Lithconia | 1802 | American | |
| Memoirs of Carwin the Biloquist | 1803 | American | |
| Kelroy | 1812 | American | |
| Precaution | 1820 | American |
3.1 Getting More Titles: British Texts
After saving this data frame of American novels to its own variable, it’s a cinch to go back and rerun everything for a similar British set:
# Save the American set
corpus_american19 <- works_df2
# Do everything again for the British set
# Start with the category URL
wp_categories_british <- "https://en.wikipedia.org/wiki/Category:19th-century_British_novels"
# Download pages only if they haven't been downloaded
if(!file.exists("British-years.html")){
download.file(wp_categories_british,
destfile = "British-years.html")}
# Parse for individual years
wp_years_links_brit <- read_html("British-years.html") %>%
html_nodes("a.CategoryTreeLabelCategory") %>%
html_attr("href")
# Get the relevant subset
wp_years_links_brit <- wp_years_links_brit[1:97]
# Download the year subcategory pages
download_wikipedia_pages(pagelist=wp_years_links_brit, number=100, group="British")
# Parse titles
get_titles(group="British")
#Tidy the titles
clean_works_df()
# Save the British set
corpus_british19 <- works_df23.2 Getting More Titles: 20th-Century Texts
Since the copyright watershed is currently ~1923, I wanted to include texts before that date, too. Our functions make this easy to repeat all of the above for years 1901-1930:
# Start with American works
wp_categories_american_20 <- "https://en.wikipedia.org/wiki/Category:20th-century_American_novels"
# Download pages that haven't been downloaded
if(!file.exists("American-years-20.html")){
download.file(wp_categories_american_20,
destfile = "American-years-20.html")
}
# Parse for individual years
wp_years_links_amer_20 <- read_html("American-years-20.html") %>%
html_nodes("a.CategoryTreeLabelCategory") %>%
html_attr("href")
# Limit to the first 30 items
wp_years_links_amer_20 <- wp_years_links_amer_20[1:30]
# Download the year subcategory pages
download_wikipedia_pages(pagelist=wp_years_links_amer_20,
number=100,
group="American-20")
# Parse titles
get_titles(years=1901:1930, group="American-20")
# Tidy the titles
clean_works_df()
# Save the set
corpus_american20 <- works_df2
##############
# Repeat with British works
wp_categories_british_20 <- "https://en.wikipedia.org/wiki/Category:20th-century_British_novels"
# Download pages that haven't been downloaded
if(!file.exists("British-years-20.html")){
download.file(wp_categories_british_20,
destfile = "British-years-20.html")
}
# Parse for individual years
wp_years_links_brit_20 <- read_html("British-years-20.html") %>%
html_nodes("a.CategoryTreeLabelCategory") %>%
html_attr("href")
# Limit to the first 30 items
wp_years_links_brit_20 <- wp_years_links_brit_20[1:30]
# Download the year subcategory pages
download_wikipedia_pages(pagelist=wp_years_links_brit_20,
number=100,
group="British-20")
# Parse titles
get_titles(years=1901:1930,
group="British-20")
# Tidy the titles
clean_works_df()
# Save the set
corpus_british20 <- works_df23.3 The data so far…
At this point, we have four tables:
- 19th-century American novels
- 19th-century British novels
- early 20th-century American novels
- early 20th-century British novels
Each table contains rows corresponding to novels, with columns listed for the novel’s title, its year of publication, its grouping, and (for some texts) a guess of the author’s name. Here’s what the first few rows of the table for early 20th-century British novels looks like, for reference:
| titles | year | group | possibleauthor |
|---|---|---|---|
| Anna Lombard | 1901 | British-20 | |
| Erewhon Revisited | 1901 | British-20 | |
| The First Men in the Moon | 1901 | British-20 | |
| The House with the Green Shutters | 1901 | British-20 | |
| The Inheritors | 1901 | British-20 | Conrad and Ford |
Everything here looks as we might expect it.
4 Understanding the Results
I like dipping into the data a few rows at a time like this to see how things look; it’s a good way of paying attention to the structure of information and thinking about what might be done with it. But I also think it’s important to picture the big shape of everything from a distance, too, to know where gaps stand out, to get a sense of the sheer size of things, and maybe even to think about what’s responsible for giving it shape.
In order to visualize the content of my corpus, I combined the four tables into one and charted the contents as a bar graph over time:
corpus_combined <- rbind(corpus_american19,
corpus_british19,
corpus_american20,
corpus_british20)
ggplot(corpus_combined) +
geom_bar(mapping=aes(x=year, fill=group)) +
scale_x_continuous(breaks = c(0:13*10+1800)) +
xlab(NULL) +
ylab("number of novels") +
ggtitle("Novels listed on Wikipedia per year") +
theme_bw()
Altogether, scraping these categorized titles from Wikipedia resulted in 1,907 novels. These break down into 289 American novels from the 19th century, 578 British novels from the 19th century, 568 American novels from the early 20th century, and 546 British novels from the early 20th century.
Looking at the big chart, it’s easy to see the American publishing industry gets a slow start through the 19th century before taking off in the 1890s—perhaps as a result of Congress passing the International Copyright Act of 1891. A focused view of American works makes this shift more obvious.
ggplot(corpus_combined[corpus_combined$group %in% c("American","American-20"),]) +
geom_bar(mapping=aes(x=year)) +
scale_x_continuous(breaks = c(0:13*10+1800)) +
xlab(NULL) +
ylab("number of novels") +
ggtitle("American novels categorized on Wikipedia") +
geom_segment(aes(x=1891, xend=1891, y=0, yend=32), color="red") +
geom_label(aes(x=1875, y=32), label="International Copyright Act of 1891", color="red") +
theme_bw()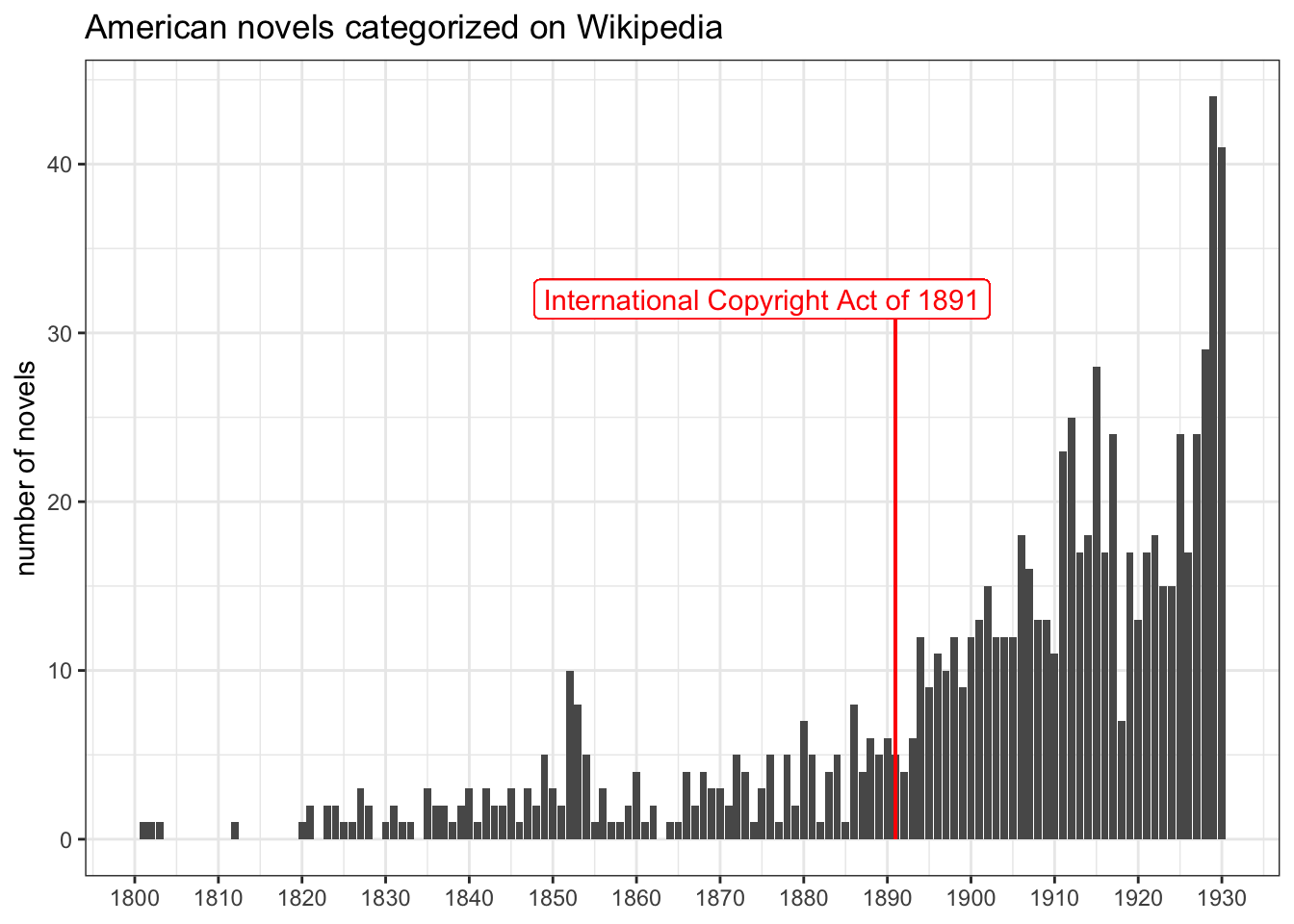
The colorful chart also shows a strong dip in the mid 1910s, which looks like it correlates to the first World War. We can zoom into that data to see it closer.
corpus_byyear <- corpus_combined %>%
group_by(year) %>%
summarize(count=n())
highlight_wwi <- data.frame(x=1914,xend=1918.4,y=0:30*2)
ggplot(corpus_combined[corpus_combined$year %in% 1905:1925,],
aes(x=year)) +
geom_segment(data=highlight_wwi,
aes(x=x,xend=xend,y=y,yend=y),
color="pink") +
geom_bar() +
geom_smooth(data=corpus_byyear[corpus_byyear$year %in% 1905:1925,],
mapping=aes(y=count,x=year),
color="red") +
scale_x_continuous(breaks = c(0:9*2+1906)) +
xlab(NULL) +
ylab("number of novels") +
ggtitle("Wikipedia's English-language novels, 1905-1925") +
geom_label(aes(x=1916.2, y=5),
label="World War I\n7/1914 - 11/1918",
color="red") +
theme_bw()
A cursory look at the combined corpus in the first chart was enough to see aberrations in the overall shapes of the numbers, prompting closer considerations. The shift of American publishing in the second chart and the drop in combined British and American publishing in the third chart might incite some research for which I now have an appropriate corpus to consult. A number of inquiries might be worth pursuing:
- does the increase in American novels from the 1890s correlate to similar changes in copyright over time and internationally? To study this, I might get new corpora from Wikipedia, or I might change gears back to non-digital research methods.
- does this 1918 fall in numbers represent a drop in publishing, a drop in quality of works, or a deficiency in Wikipedia’s representation of published works? To study this, I might look into the history of publishing, I might try to find some other method for measuring the shaping of a contemporary canon,6 or I might dive into the editing history of these Wikipedia categories.
- does the valley during WWI correspond to valleys at other moments of wartime or to peaks during periods of peace? do these peaks and valleys perhaps correlate instead to purely economic numbers? is it possible that the 1891 law or the first world war is unrelated to any shifting? To study this, I’d have to find some other world war to compare it to, or I’d have to look closer at other periods of economic instability.
But these are questions for another day.
5 Conclusions
Wikipedia is far from perfect, but it’s closer than I am in avoiding selection bias. Seeing this chart helps me feel comfortable that I haven’t unwittingly left something out and confident that I’m not amplifying my own limited knowledge of available texts.
After all this work, it’s a really good idea to save the final table to external files to have a milestone to start back from another time. Saving as both an RDS file and a CSV file makes it easy to reuse the data in R or in any other common application.7
saveRDS(corpus_combined,file="corpus_combined.rds")
write.csv(corpus_combined,file="corpus_combined.csv", row.names=FALSE)Footnotes
There’s a lot of code here. If that isn’t your thing, there’s no shame in skipping ahead to the pictures if you prefer starting with dessert.↩︎
More rough Googling suggests there are 34 million users, but these numbers are probably worldwide; at least some of these users don’t speak English, and a subset of English speakers have probably never used their accounts to contribute.↩︎
I’m starting with the category of 19th-century American novels, but I’ll later on add 19th-century British novels, 20th-century American novels, and 20th-century British novels. With variation, similar corpora could be created by referencing other centuries, other nationalities, or even other generic groupings, like American novels by genre.↩︎
This may have been unnecessary, but discretion is the botter’s part of valor.↩︎
Foreshadowing!↩︎
More foreshadowing for a future post!↩︎
My files are available for download here: corpus_combined.rds, corpus_combined.csv“).↩︎
Citation
BibTeX citation:
@misc{clawson2019,
author = {Clawson, James},
title = {Selecting a {Literary} {Corpus} from {Wikipedia}},
date = {2019-03-27},
url = {https://jmclawson.net/posts/selecting-a-literary-corpus-from-wikipedia/},
langid = {en}
}
For attribution, please cite this work as:
Clawson, James. “Selecting a Literary Corpus from
Wikipedia.” jmclawson.net,
27 Mar. 2019, https://jmclawson.net/posts/selecting-a-literary-corpus-from-wikipedia/.